Nucleic acids such as deoxyribonucleic acid (DNA) and
ribonucleic acid (RNA) are polymers.
These polymers have special significance in living cells as
they carry the genetic information
of the organism. Coded in the DNA is the information used to control cell growth and development as
well as the information needed to carry out all the processes which keep the cell and ultimately
the organism alive, this genetic information is stored in a sequence of nucleotides. DNA is a very large molecule and like many large molecules it is a
polymer
composed of many smaller units linked together. In the case of DNA the smaller
monomer units that
link together to form the DNA polymer are called nucleotides.
Nucleotides are the monomers from which the DNA
polymer is built. The nucleotides
consist of a base (sometimes called an amine base), a sugar molecule
and a phosphate group all linked together. An outline of how the structure of the DNA polymer is shown below. The nucleotide molecules all contain the same sugar and phosphate group but there are four possible amine bases; so there are four different nucleotides.

Ribose is a simple sugar molecule that is made in the human body. Many people; mainly athletes take ribose supplements as it is claimed to give you extra energy and reduce fatigue. Its chemical formula is C5H10O4. Its structure is shown below.
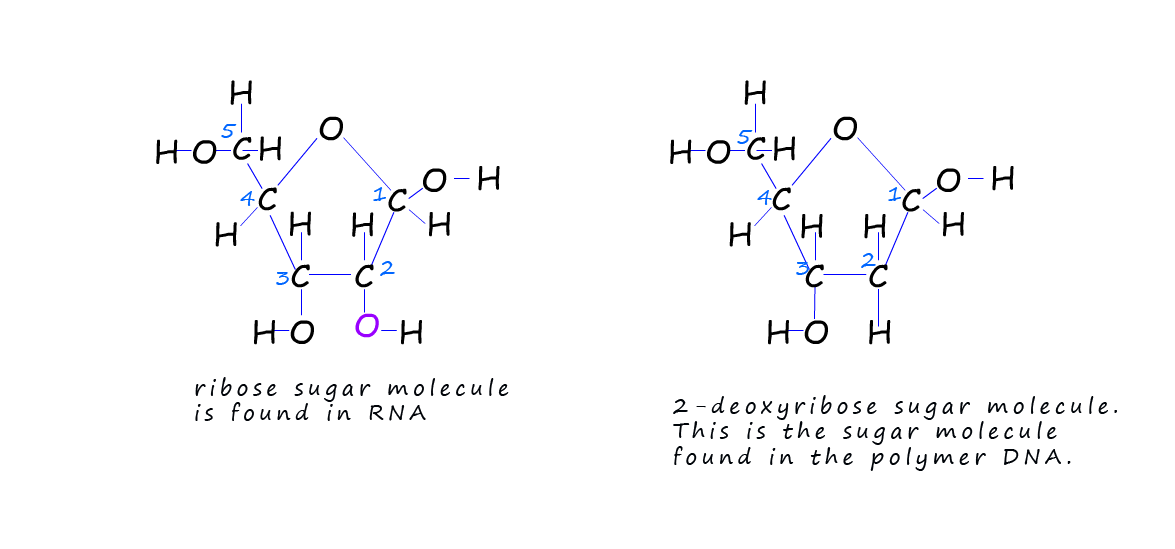
You can see that ribose sugar has a ring structure in the shape of a pentagon. The carbon atoms
in
the ring are mostly joined to a H atom and a hydroxyl (OH) group. The second sugar molecule shown is
2-deoxyribose (C5H10O4);
this is very similar to the structure of ribose sugar except there is one atom of oxygen
missing on the
second carbon atom in the ring (deoxy indicates that oxygen is missing). This sugar 2-deoxyribose is
the one found in DNA. Ribose is found in another molecule call RNA. RNA can be found in the cytoplasm of cells and is involved in the synthesis of proteins.
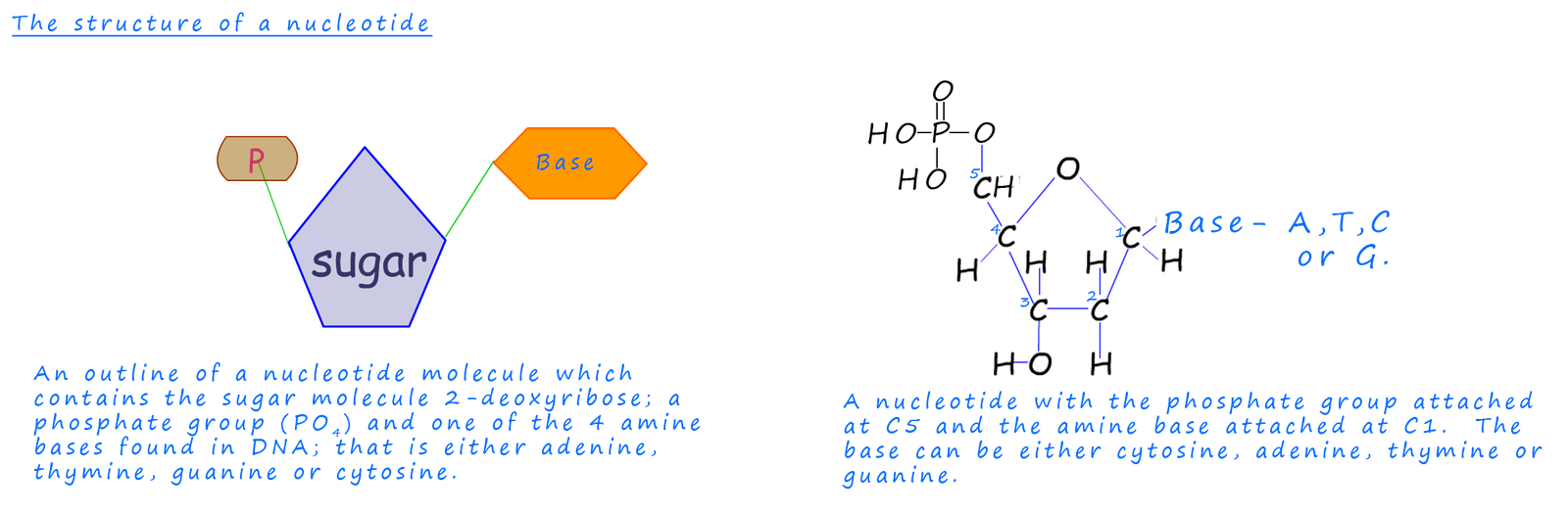
As mentioned above the monomers for the DNA polymer; the nucleotide molecules consist of a phosphate group, a sugar and a base all linked together. The sugar molecule found in DNA is called 2-deoxyribose and there are four different bases found in the nucleotides. These bases are adenine, guanine, cytosine and thymine. These names are often simply shortened to the letters A, G, C and T. The structure of these four bases is shown below:

As mentioned above the monomer used to build the DNA polymer is called a nucleotide, its structure is shown below. It consists of a sugar molecule, a phosphate group and an amine base. The base is either adenine, cytosine, guanine or thymine.
In DNA the amine base is joined to the sugar molecule at carbon atom number 1; C1 while the phosphoric acid phosphate group (PO4) is joined to the sugar molecule at carbon atom number 5; C5. This is outlined below:
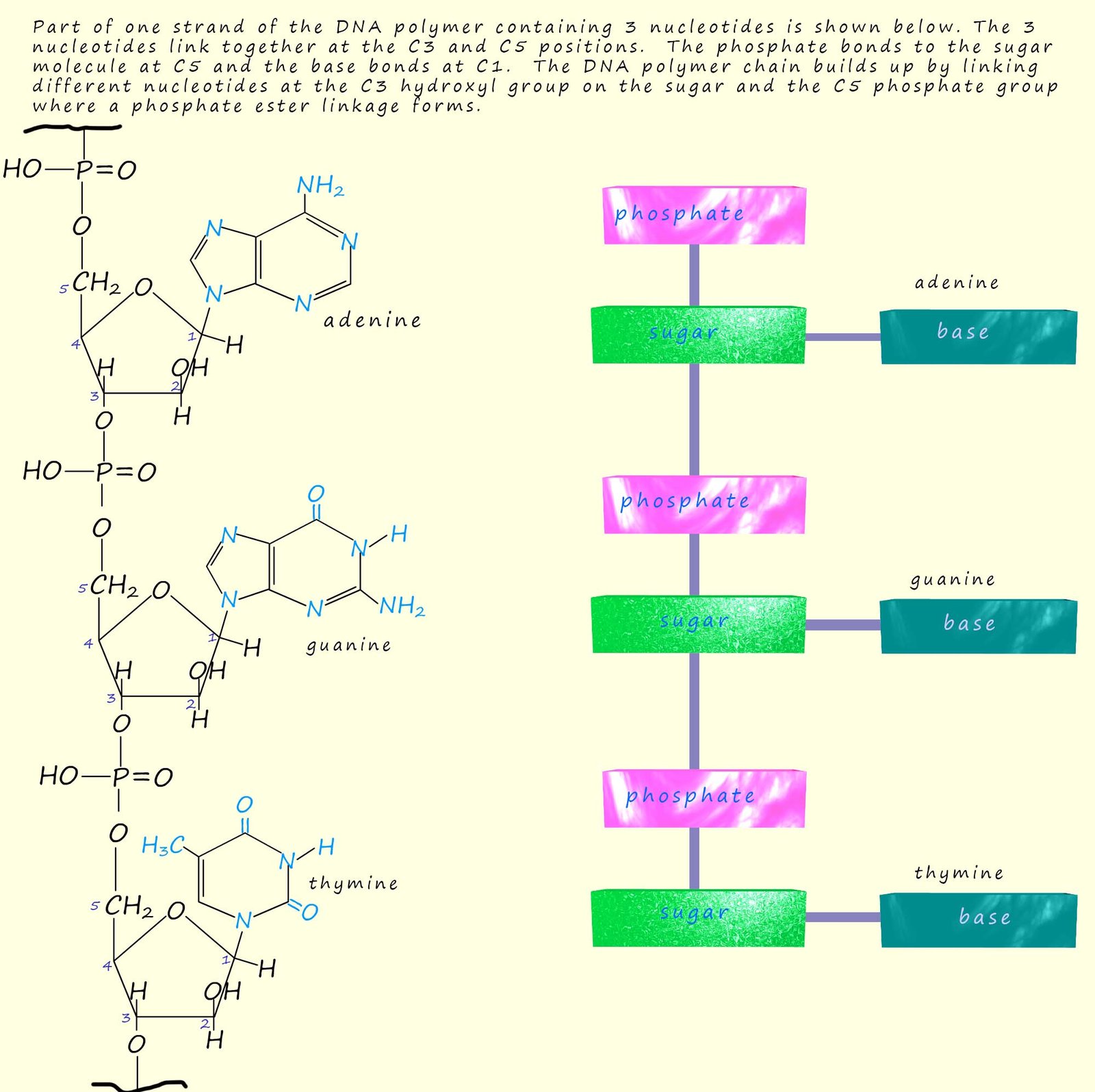
Since each nucleotide contains a phosphate group, a sugar molecule and an amine base and there are 4 different amines bases in DNA then there must be 4 different nucleotides. The diagram below shows the structure of the four different nucleotides found in DNA, at first glance they look quite complicated but they are really quite simple; the only difference between each the nucleotide is the base present.

Part of one single strand of the DNA polymer containing 3 nucleotides is shown below. The 3 nucleotides link together in a condensation reaction at the C3 and C5 positions. The phosphate group bonds to the sugar molecule at C5 and the base bonds at C1. The DNA polymer chain builds up by linking different nucleotides at the C3 hydroxyl group on the sugar molecule and the C5 phosphate group where a phosphate ester linkage forms. In the single DNA strand shown below the top of the DNA strand has carbon atom number 5 in the sugar molecule bonded to the phosphate group; often called the 5 end; at the other end of the DNA strand is another phosphate group but this time it would be bonded to carbon atom number 3 in the sugar molecule. This end is often called the 3 end. I only mention this as it will be important later when we discuss the arrangement of the nucleotides in the other DNA strand in the double helix arrangement of DNA.
In 1953 James Watson and Francis Crick suggested the structure of DNA consisted of two of these
polymer strands shown below twisted together in a double helix structure. The two strands of
nucleotides run in opposite directions to each other.
The two strands are attracted to each other
through weak intermolecular bonding between the bases on each strand. However Watson and Crick
found that the intermolecular bonding between the two strands of DNA ONLY occurs between the bases adenine (A) and thymine (T) on different
strands and between guanine (G) and cytosine (C) bases on different strands.
This is shown below using the three nucleotide monomers from above to show how the two DNA strands can become connected by hydrogen bonding between the bases. This base pairing is often referred to as AT and CG base pairing. It is important to note that the two DNA strands are not identical. The second strand; often called the complementary strand has at the top of the strand a 3-end and a 5-end at the bottom, while the first strand is the other way around.

The reason for this A......T and G.....C base pairing on different strands is simply due
to the shapes of the base molecule which allows them to fit together easily and so allows
strong intermolecular hydrogen bonding between the two DNA strands. A single strand of DNA or a selection of polynuctelotides can be represented by simply writing the order of the bases starting at the 5-end.

The structure of the DNA polymer resembles a coiled spring or to give its structure the proper name; it is referred to as a double helix (shown opposite). The phosphate groups and the sugar molecules form the strands of the helix and bases link together the two strands of DNA which make up the double helix. This gives the basic structure of DNA as shown where there is a backbone of
phosphate-sugar molecules linked up with the bases sticking out from the sugar molecules.
When cells divide and multiply the DNA inside the cells needs to be copied and replicated; this replication of DNA is an enzyme catalysed process. During the replication process the DNA double helix structure inside the cells slowly starts to unwind and is then copied. During the copying or replication stage each DNA single strand will be copied in such a way that the copy contains the sequence of the complementary nucleotides copied from the original strand. In this way both strands of nucleotides from the DNA in both strands in the starting double helix will be copied. The image below shows part of the nucleotide sequence in ONE strand of DNA and the copied complementary strand.

